Data Visualisation
Posts
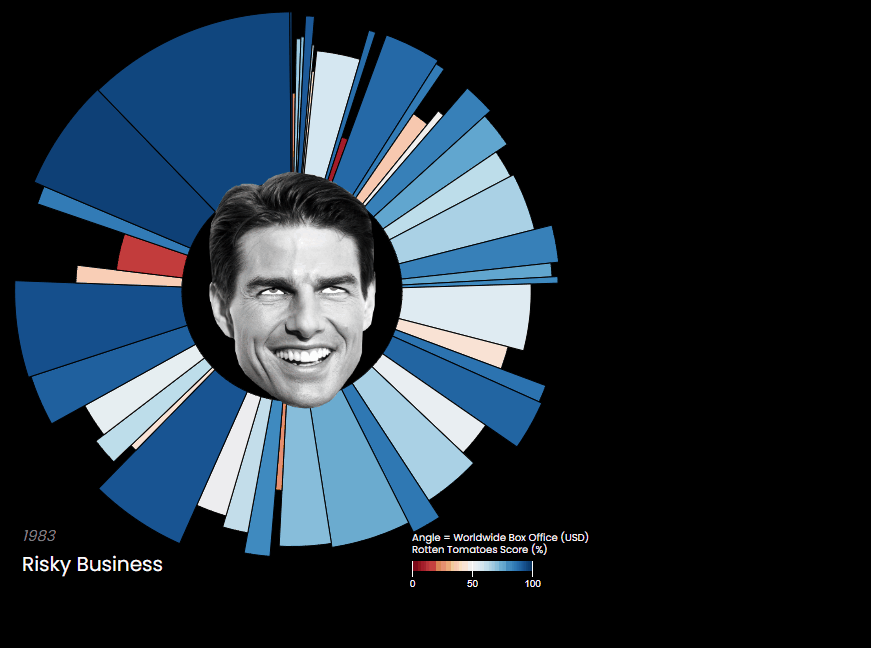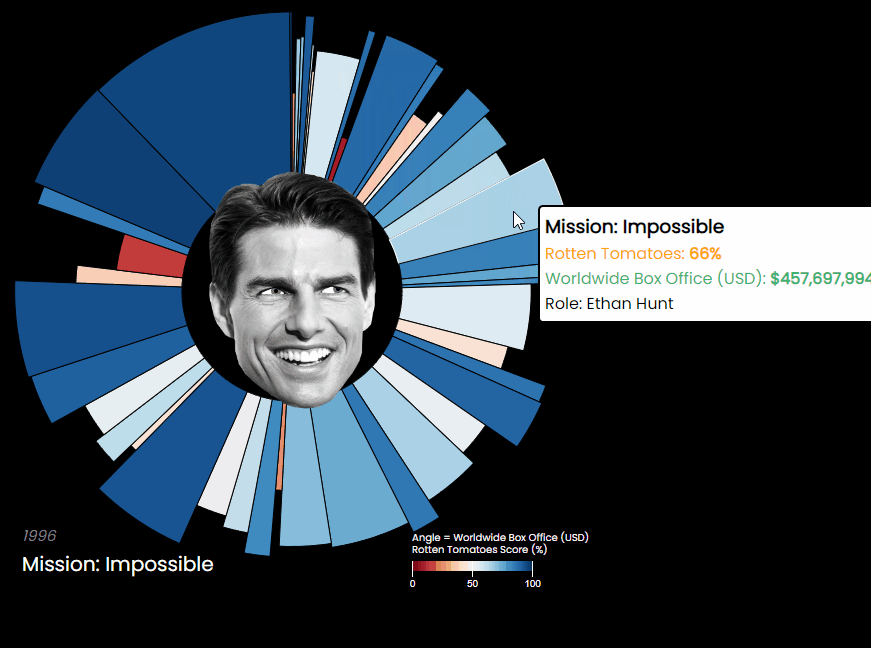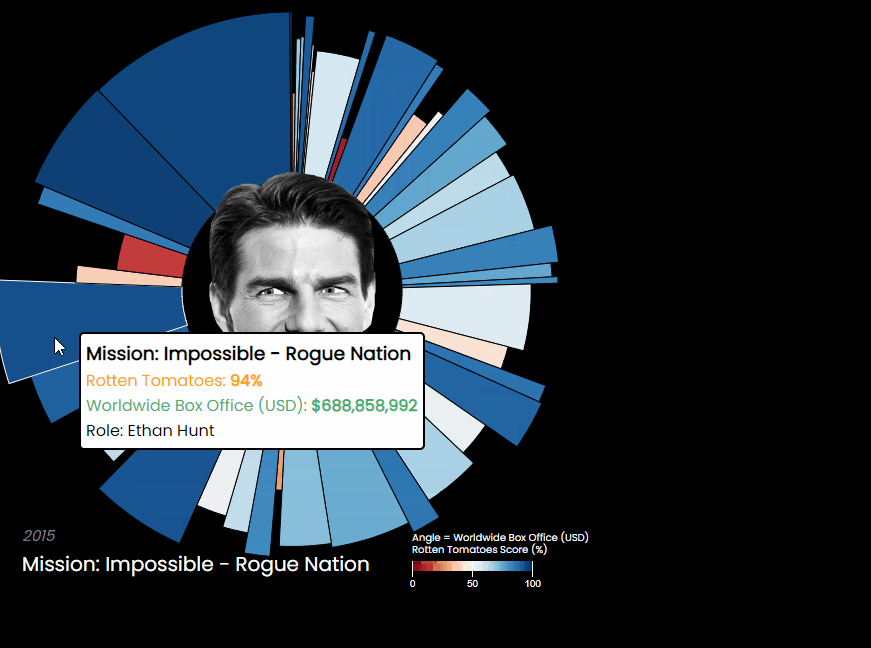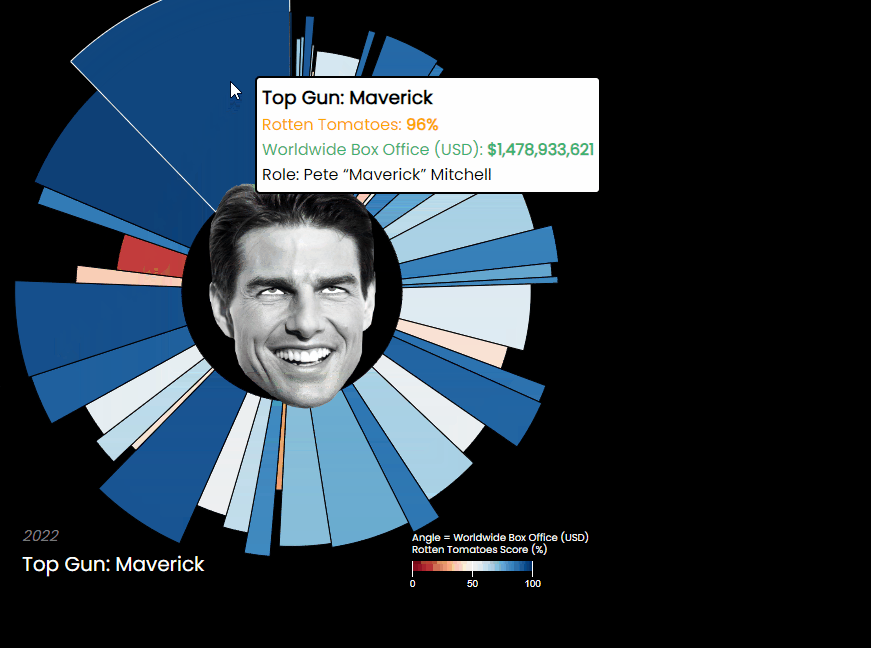

Posts



Data Engineering
Posts



Machine Learning
Posts


Risk Modelling
Posts


Natural Language Processing
Posts
