Using Python to scrape Wikipedia for images of the most viewed people in 2020
In the previous post, we acquired the hourly page views data for every page on Wikipedia, and loaded it into Google BigQuery. In this post, we’ll look at the most viewed pages each day and see which people were the most viewed on Wikipedia.
The first step is to use the table tc-wiki-2020.wikipedia.2020_en_daily_views_ranked to get every page that was in the top 50 most viewed pages each day in 2020. We can do this from Python using the BigQuery API:
How can we tell if a Wikipedia page is about a person?
The first approach I tried was to use a named-entity recognition algorithm. Unfortunately, the results were unimpressive as the titles of the pages don’t have any other words around them to give context. Another problem is that Wikipedia pages can be about things relating to a person, which would be flagged as being about the person themselves. For example, Kanye West and Kanye West albums discography are two separate articles, but we would only be interested in the former.
The solution was to simply extract the top 50 ranked pages each day (titles.csv), deduplicate on title name and manually flag pages that were about people. Not the most elegant solution, but far more accurate. Reviewing the page titles took about an hour. The criteria used was:
No fictional people (e.g. characters in a film)
No events related to people (e.g. Donald Trump 2020 presidential campaign)
No collections of people (e.g. The Beatles)
No positions (e.g. Governor of Minnesota)
No films related to people (e.g. Richard Jewell)
Pseudonyms allowed (e.g. Prince (musician)
The new titles_persons.csv then gets loaded into a dataframe and added as a table to BigQuery:
Here’s what the new dataframe of names looks like:

Getting images of the people of 2020
We want to eventually build a data visualisation of the people in our list. To make the visualisation even more interesting, we’ll include pictures of each of the people. There are a few ways to get the images:
Manually search for each person and upload to an image hosting service
We could simply Google every person in the list, and download a decent picture for each one. This would take a long time, as the persons list has over 1400 people on it.
Use a Google image search API to automate the search for images
Google provides a Custom Search API that lets us retrieve and display search results (including images) from Google programmatically. The library Google-Images-Search gives an interface to the API through Python. Using the API would get our images far more quickly, but we’d likely run into issues with data quality. For example, the first Google image search result for Tom Hanks shows a picture of Tom and his wife, Rita Wilson. We could use the OpenCV Python library to run facial recognition and crop the faces in each image, but we’d still have to manually check which face corresponded to which person.
Scrape the images from Wikipedia directly
Most Wikipedia pages have a section called the ‘infobox’ on the right side of the page. In the infobox for the people we’re interested in, there is usually a representative image of that person:
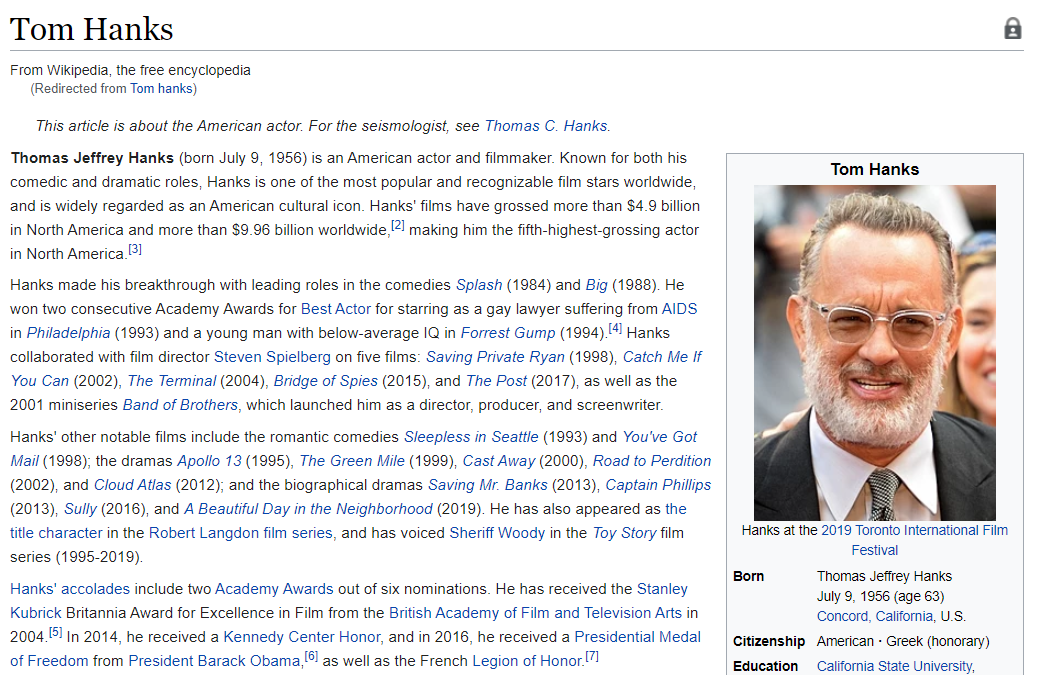
We know the exact names of the Wikipedia pages we’re interested in. With this information, we can use the Beautiful Soup library to scrape the image URLs from Wikipedia. Another advantage of this approach is that Wikipedia hosts the images, so we won’t need to upload and host the images ourselves.
After running the script above, we can have a look at the results in the title_urls table:

And see if the images look representative:

Looks pretty good! There are around 200 pages out of ~1400 where we couldn’t find images. Not unusual, as some Wikipedia pages don’t include images of the person. We now have everything we need to build a table of the top ranked people each day.
Here’s what our final table looks like:
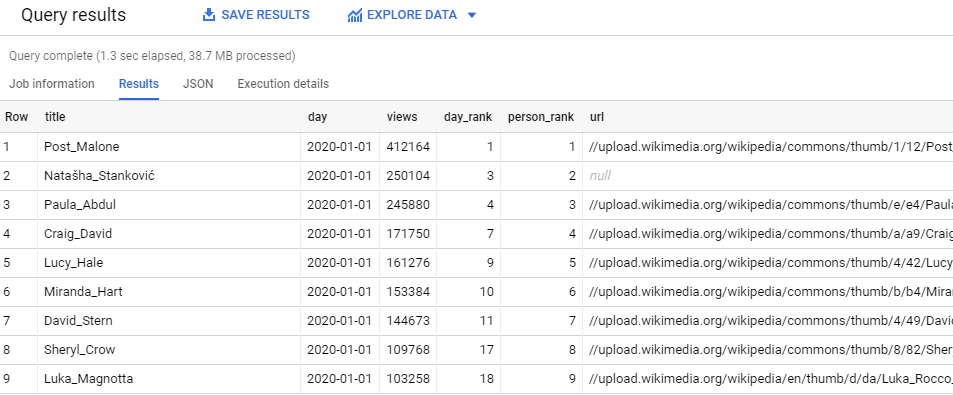
A point to note about the table above - the page for Nataša Stanković does have an image linked, but on the 1st of January 2020, Wikipedia had Nataša’s page incorrectly named as ‘Natašha Stanković‘. Our script joins on the title of the given page at that particular date, so we’re missing the most up to date image. This happens fairly rarely however, so we’ll leave it as is.
Whats next?
We now have the table ranking the pages for people in 2020, along with images of each. The process is mostly streamlined, with the exception of finding ‘people’ in the list of all Wikipedia pages. We may be able to improve the automation of this step in future using Wikidata’s published metadata about each page. Property ‘Q5’ indicates that the page is an instance of a ‘human’. We would need to investigate to see how consistently each page is tagged with the Q5 property. In the next post, we’ll build a ‘racing bar chart’ to show which people were the most viewed in 2020 each day.